
Lessons on life and humor from GPT2
GPT2 makes you think; GPT5 thinks for you.

I won’t spend much time writing our shared concerns about the negative impact of powerful language models on our society, economy, mental health, and cognitive faculties. I will summarize it thusly:
The risk of modern LLMs like GPT5 is that we offload so much of our cognitive function to AI that our critical thinking skills diminish.
But I want this post to be positive. There’s plenty of other writing online about AI risks.
GPT2 is my favorite of the GPT lines. It is not the most capable. It can’t code for shit. It can’t stay on-topic for more than a few sentences.
But it is hilarious and has some amazing insights into life, the universe, and everything.
The goal of this post is to show you how to import GPT2 into Python, give it a prompt, and have it generate new tokens. I’ll sprinkle in a bit of education about how LLMs work, cuz that’s my style.
How language models generate new text
I discuss LLM mechanisms in more detail in my 6-part series — and in much much more detail in my video-based online course, but here is a very brief, nontechnical overview:
When you prompt an LLM like ChatGPT, the text you write gets converted into numbers — first into integers (e.g., “hello” becomes #15496) and then into coordinates in a high-dimensional space (think of a 2D graph in which “hello” appears at a specific [x,y] coordinate, but with thousands of dimensions instead of two). That coordinate representation is formally called an embeddings vector, and it’s used to predict what word should come next.
Each time the language model sees a word, it generates a prediction about what word comes next. The LLM can only ever use one word to predict the next word. So when the model sees the embeddings vector for the word “hello”, it might predict that the next word should be “there”.
But here’s the thing: Each word’s embeddings vector is not fixed; it gets modified according to context (previous words) and world-knowledge (rich and complex associations between words that the model has learned from being trained on most of the Internet). That modification takes place inside the transformer block, which implements the attention algorithm.
Consider the text in the figure below. When the model processes each word, it makes a prediction about what word should come next.

So when the model generates a prediction for what should come after “in”, it is, in a literally sense, only using the word “in” to predict that next word. However, the embeddings vector for “in” is modified by all the words before it — plus all the world-knowledge that isn’t in the prompt, for example that oat milk goes in coffee and cereal, it’s more expensive than cow milk, vegans drink it, etc.
So how does a language model generate a reply to your prompt? It does it one word at a time. It reads your prompt and generates one new token at the end (for example, it might generate “coffee” in the example shown above). Then it reads your prompt and its previous-generated token, and then generates one more new token (for example, it might produce “I prefer oat milk in coffee and”). Then it again takes your prompt, its two generated tokens, and generates one more. That keeps going until a set number of tokens, or when it produces a special “end-of-sequence” token.
Enough talk! Let’s get ourselves some GPT2 wisdom.
The rest of this post is an explanation of a demo that you can run. It’s in Python, you can get the code on my GitHub using this link, and I recommend running this code using Google’s colab service, so that you won’t need to worry about version-control or installing libraries.
Brand-new to Python?
If you have no (or very little) experience with Python but still want to run the code, then skim the post and watch the video at the end! I will walk you through exactly how to run the code. All you need is a Google account.
Importing and preparing GPT2
There are five versions of the GPT2 model that are available; here I’ll use the “medium” version. It has 355 million parameters. That’s a lot parameters if you had a lollipop for each one, but it’s actually quite small for LLMs. For reference, GPT4 has around 1.7 TRILLION parameters.

That code block also checks whether the Python session is hooked up to a GPU, and moves the model onto the GPU. We’re not going to do a lot of intense processing in this demo, so you don’t actually *need* a GPU to run the code. It will be the difference between waiting 2-5 seconds vs. tens of seconds.
Writing and tokenizing a prompt
The next step is to write a prompt and transform it into tokens. “Tokens” is the official term for whole numbers that represent words (it’s actually more complicated that this because tokens actually encode byte sequences not words, but that nuance is not relevant here).

If you want to learn more about tokenization, check out Part 1 of my 6-part series on LLM mechanisms.
The next step is to have the language model generate new tokens. For that you can use the method generate on the model object. There are many optional arguments you can input to the method. The most relevant ones for our purposes are
max_length, which is the maximum number of tokens that GPT2 will output (the relationship between tokens and words is complicated, but as a rough approximation, you can say that 1 token ≈ 1 word).do_sample, which allows the model to sample tokens with some randomness instead of choosing tokens deterministically. The sampling is not completely random, but instead is focused on a small selection of tokens that the model considers most likely. That selection is governed by thetop_kandtop_pparameters.
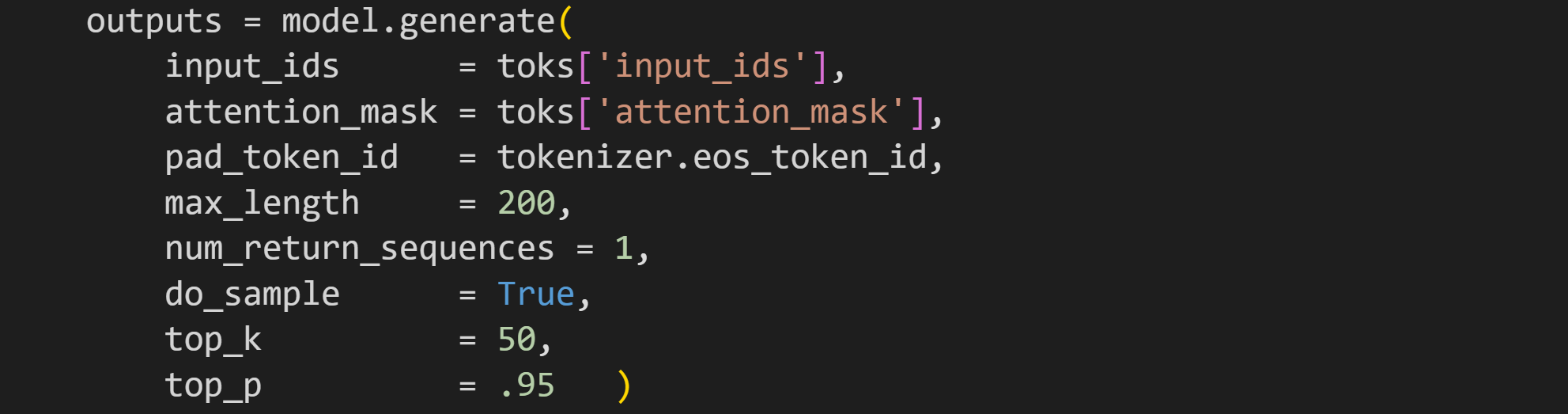
If you’re curious, then of course I recommend experimenting with those parameters, but it’s fine to leave them at the values I’ve specified.
The variable outputs contains both the prompt and the model’s reply. The code below extracts the tokens from the model that come after the prompt that you supplied, then prints it out.
And voila! Enjoy the wisdom of GPT2:

What can we learn from GPT2?
GPT2 has a good (though imperfect) grasp of grammar and writing style, yet has an absolutely abysmal understanding of the world. It cannot recite facts or help you with your algebra homework or really do anything of practical use.
But it makes me laugh and makes me think, and that’s good enough.
Here’s a video walk-through of how to get and run the code. If you’re an experienced Pythoneer, you don’t need to watch it.