
LLM breakdown 1/6: Tokenization (words to integers)
Large language models can't read; instead, they are given numbers that come from text.

About this 6-part series
Educational material on large language models (LLMs) comes in one of two categories: (1) high-level overviews that avoid details; or (2) highly technical tutorials written for computer scientists. Both of these approaches are valuable, and any engagement with technical topics should be encouraged and supported (though the first category risks the illusion of understanding something that isn’t actually understood).
But I think there’s a better way.
My approach is to demonstrate how LLMs work by analyzing their internal mechanisms (weights and activations) using machine learning. Many people with data science backgrounds could benefit from an approach that leverages their skills with data, rather than assuming they are comfortable with advanced mathematics.
You not just going to look at equations and code; you’re going to dissect the model while it’s processing text, extract activations, and perform analyses and visualizations on those internal activations. It’s kind of like doing neuroscience research, except that an LLM is absolutely nothing whatsoever like a real brain (I’m a former neuroscience professor).
Each post in this series will have three main parts:
Explaining the model component using English, pictures, and code.
Peering into the model by extracting model internal activations to perform machine-learning analyses on the data.
Manipulating the internals of the model during inference to examine the impact of manipulating the model on its ability to process language.
(Actually, this first post is a bit different in that tokenization happens before LLM processing, and so only includes part 1.)
Prerequisites. I assume no background knowledge other than high-school-level math proficiency. If you want to follow along in the online code file, you’ll need some coding familiarity.
In the video below, I show how to get the code notebook file from the link above into Google Colab via GitHub.
What are tokens and why are they important?
Language models like ChatGPT and Claude don’t work with text. That’s because LLMs are based on mathematics, and math works on numbers, not on words. Therefore, LLMs need to work on numbers.
Tokenization is the process of converting written language into integers (an integer is a whole number). You might think that tokenization is as simple as a=1, b=2, c=3, etc. That is one way to tokenize text, but it turns out that it’s not the only way — and certainly not the most optimal way. For example, the figure below shows three ways to represent the word “Hello” using integers.
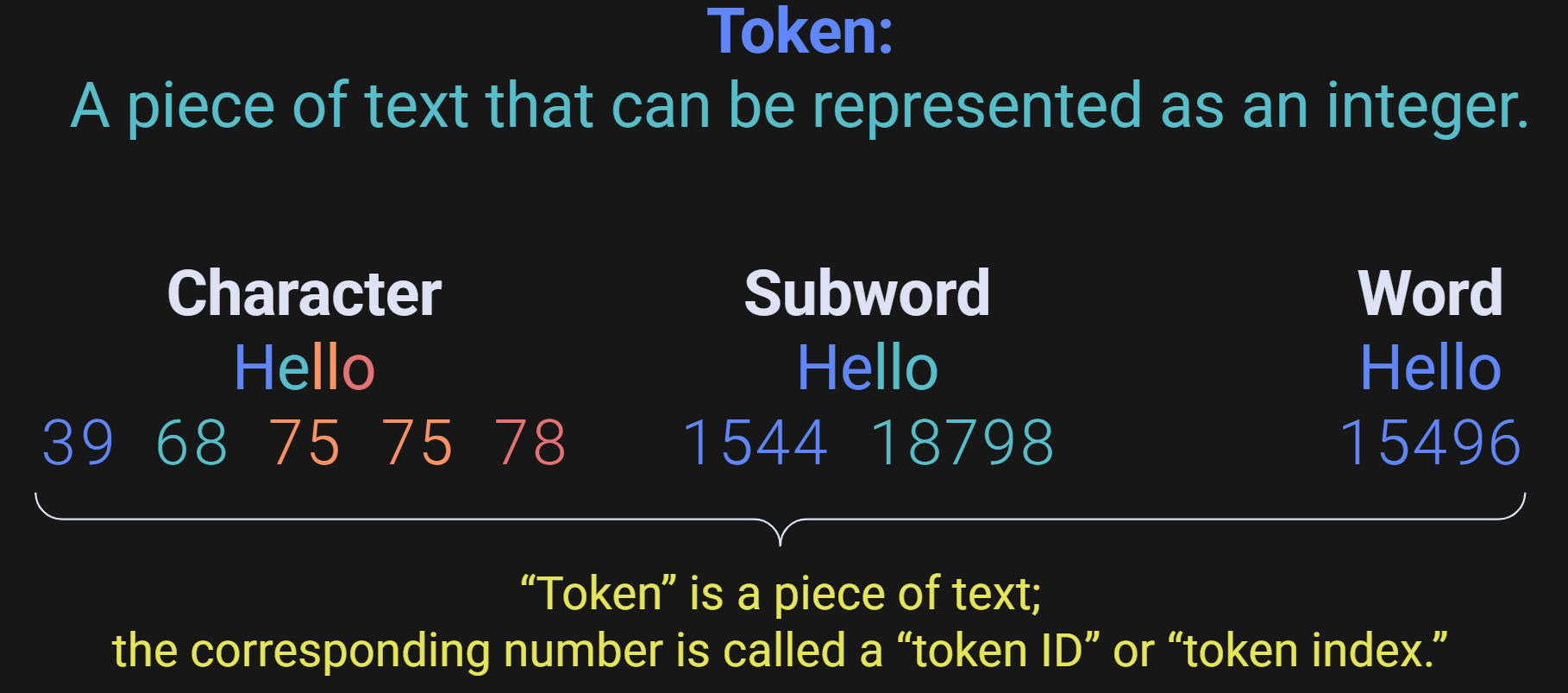
The figure shows three tokenization schemes, but it’s not the case that you choose which scheme to use; tokenization is learned from text data based on an algorithm that I will describe later in this post. In OpenAI’s GPT models, most English words are represented using one or a small number of tokens.
Tokens are great because they are efficient. Using one token to encode “hello” means that the language model has less data to process (which means cheaper and faster runs), and therefore can have a longer context window for generating relevant text. As a simple example, the world “hello” has a tokenization compression ratio of 5:1 (5 characters —> 1 token). Let’s imagine that this is a reasonable average for all words. And imagine we have an LLM with a maximum sequence length of 1000 integers. 1000 tokens is around 5000 characters (1000 words), whereas 1000 characters is around 200 words. (This example is overly simplistic, but it does capture the main idea.)
Where does tokenization happen during LLM processing? Tokenization actually happens before the model sees any data. In fact, I don’t even import any language models in the code file for this post. The “tokenizer” is a Python class (a variable with some specialized functions attached) that takes text as input and gives a list of integers as output.
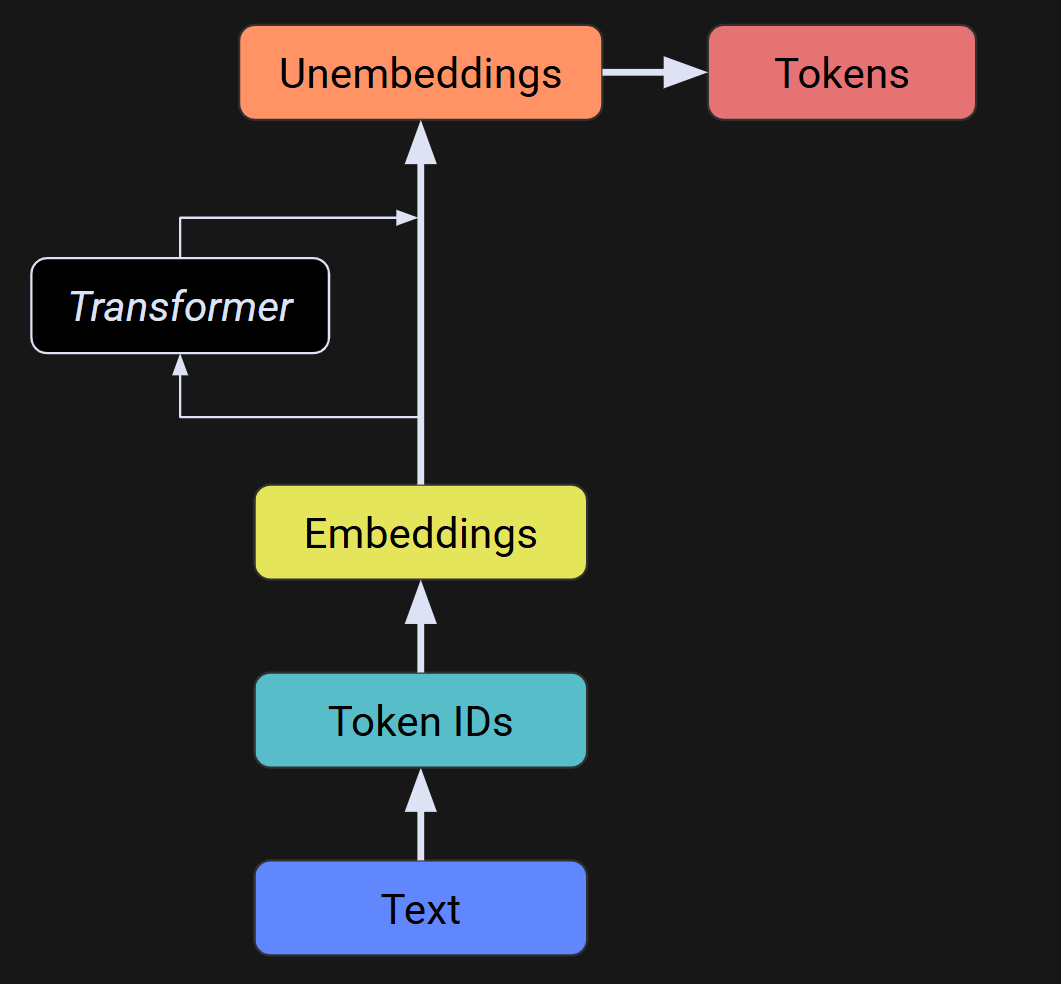
The figure below shows a broad outline of information flow in an LLM. You start with text at the bottom, which is then tokenized (green box). The first step of the LLM is to transform the tokens into “embeddings vectors,” which is the main topic of Part 3 of this series. Then there’s the heart of LLMs — the sequence of transformer blocks, including the famous “attention” mechanism, that I’ll introduce you to in Parts 4-6. After all the transformations, we have an "unembeddings” matrix, which is basically just transforming the embeddings vectors back to tokens and then to text.
Will more advanced future language models continue to use tokens? I gave up predicting the future, so I won’t take a stance. Some people argue that byte-level encoding is the future because it’s simpler and more universal (e.g., emojis, lots of languages) — but it requires A LOT more memory and training, and it’s not clear that there is enough high-quality data to train on, and whether the increased memory requirements are worth it. Tokenization may be imperfect, but it compresses language and removes redundancies (e.g., “the” becomes one number instead of three).
Tokenization in GPT2
Let’s explore! Here’s some code to import OpenAI’s tokenizer for its GPT2 family of models:

transformers is a library provided by HuggingFace, which is an AI org that provides lots of freely available models and datasets.
As a reminder for all of my posts: I show only the essential code in the post, and have a dedicated Python notebook file on GitHub just for this post. I encourage you to use that code file to reproduce and continue exploring the code I show here.
The code dir(tokenizer) lists the attributes and methods associated with an object. Whenever you start exploring a new variable class in Python, it’s a good idea to dir it. The tokenizer instance has many properties; here are a few:
There is an attribute called vocab_size, which tells us how big the GPT2 lexicon is.
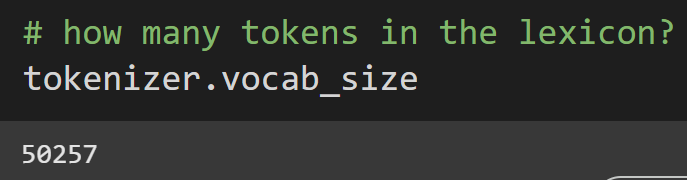
There are 50,257 tokens in the vocab. That corresponds to all the alphanumeric characters and 50k subwords. Here are few random tokens:
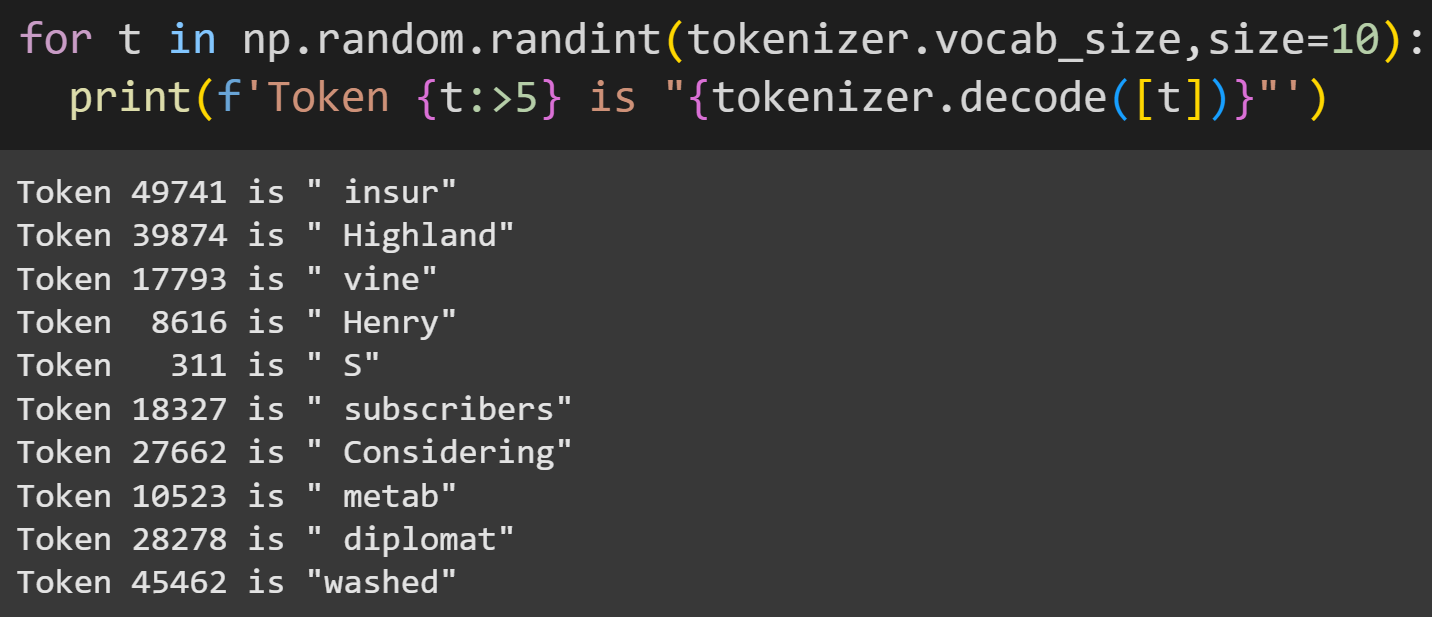
Notice that some tokens are full words (e.g., Highland) while others are subwords (e.g., “metab,” which could be part of “metabolism” and “metabolite”). Also notice that some tokens have preceding spaces while others don’t. More on that in a moment!
Those are randomly selected individual tokens. How does text tokenization work? Well, the details of tokenizing text are not so difficult, but I’m not going to go into them here. Suffice it to say that there is an algorithm called byte-pair encoding (BPE), which finds an optimal way of chunking text into tokens based on co-occurrences in text data. For example, the letter pair “th” appears very often in written English compared to “tq,” and so “th” will be combined into a token while “tq” will not. (Indeed, you can confirm in the online code that “th” is one token while “tq” is two tokens.)
Anyway, the idea is that the tokenizer scans through text and finds the optimal way to combine character sequences to form tokens. Here’s an example of tokenizing the sentence “I like the longer-form posts on Substack.”
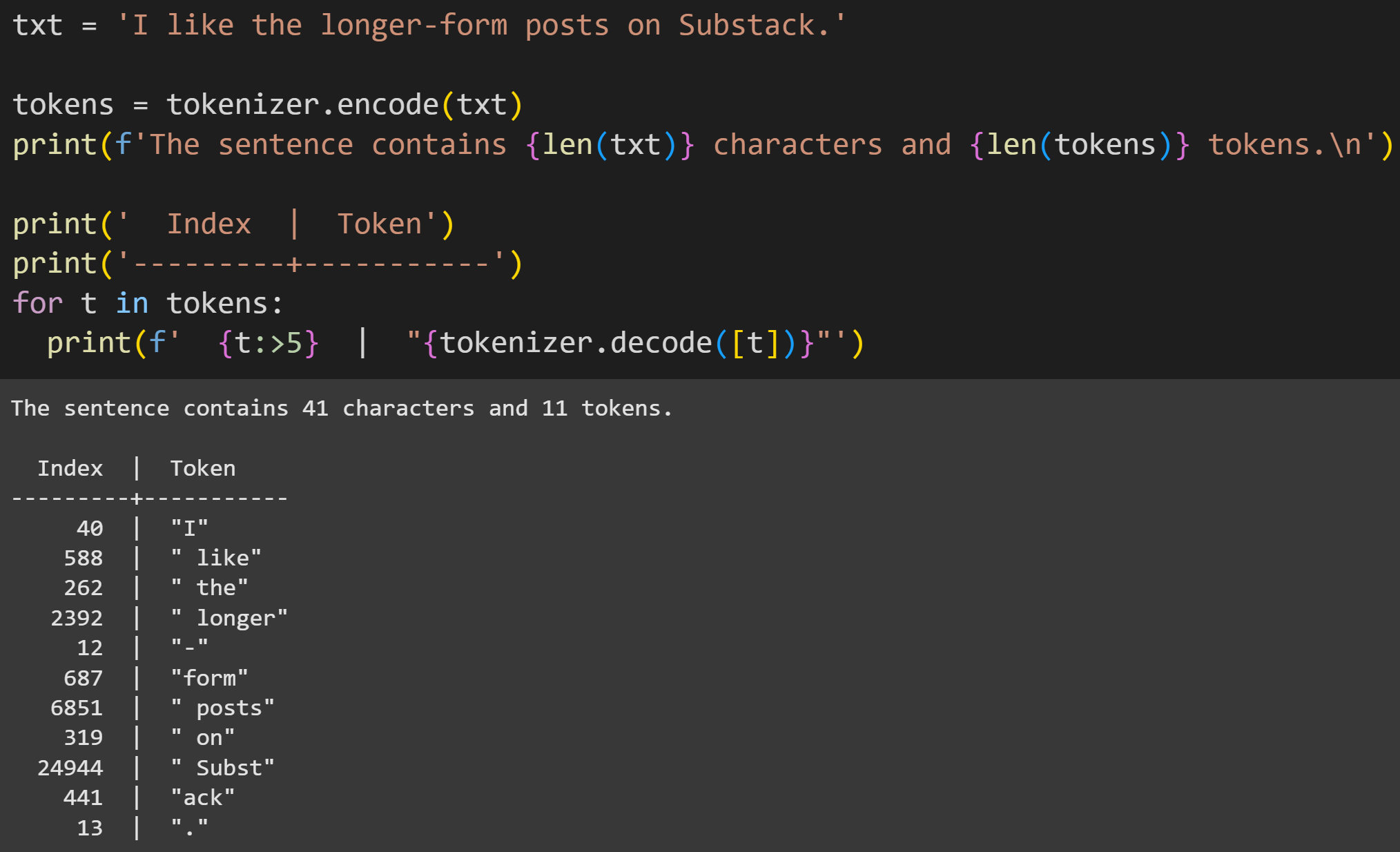
41 characters vs. 11 tokens means a ~75% compression ratio. That’s advantageous because it means the LLM needs fewer resources, and can maintain a longer history of text to general context-relevant responses, when using tokens instead of individual characters.
The importance of emptiness (spaces)
What’s the deal with the preceding spaces? First of all, they are not random and they are not arbitrary. Watch how GPT2 tokenizes the same words with and without a preceding space:
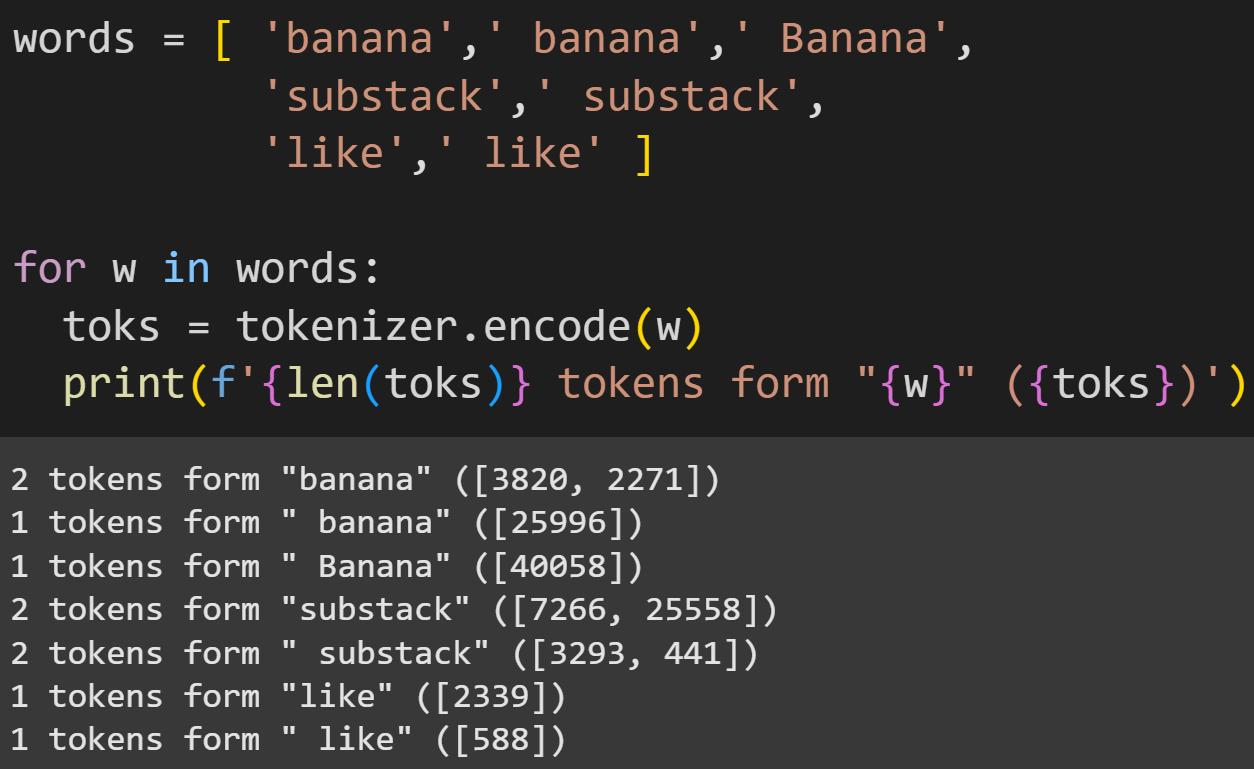
These examples reveal four interesting properties of tokenization: (1) some words are one token with a space (“ banana”) but more than one token without a space (“banana”); (2) capitalization matters (at least for some tokenizers; I’ll get back to this point later in the post); (3) some words comprise two tokens with or without a space, but the tokens differ; (4) some words (“like” and “ like”) are single-tokens with or without a space — but again those tokens differ.
That’s interesting to think about because to us humans, “like” and “ like” are the same word, but to an LLM like GPT, those are completely separate vocab items. Through training, the models eventually learn that tokens 2339 and 588 can be conceptually identical, or they can have distinct meanings if “like” is a subwords (e.g., unlike vs. alike vs. businesslike).
Language looks very different to us humans vs. to LLMs. We understand that spaces are not intrinsically meaningful; they simply separate words. But LLMs don’t read words; they read token sequences. And those token sequences are based on statistical occurrences in written text, not on the meaning of the characters (models learn meaning during training, but that happens after the tokenization).
How many "r"s in strawberry?
Perhaps you’ve come across an article or social media post about how ChatGPT can’t count letters. You ask ChatGPT to count the number of “r”s in the word “strawberry” and it will say something like 1 or 2 (there are, in fact, three “r”s). That gets a sensible chuckle, because how are we supposed to believe that AI will put us all out of work, run the world, and possibly kill us all if it can’t even count letters??!
Here’s the thing: ChatGPT doesn’t know how many “r”s are in strawberry, because what we see as the word “ strawberry” GPT sees as token 41236. The letter “r” is token 81. Does the number 81 appear in the number 41236? Nope! Therefore, there are ZERO “r”s in “ strawberry”.
In general, if you want ChatGPT (or any other LLM like Claude or Gemini or Deepseek) to give you a more accurate reply to questions like this, don’t ask for the answer; ask for it to write code that will calculate the answer. ChatGPT will then write Python code that spells out the word and counts the number of times a particular character appears.
That said, once these kind of funny-yet-embarrassing quirks become public, AI companies will fine-tune their models to handle these situations. Watch what happens in GPT5:
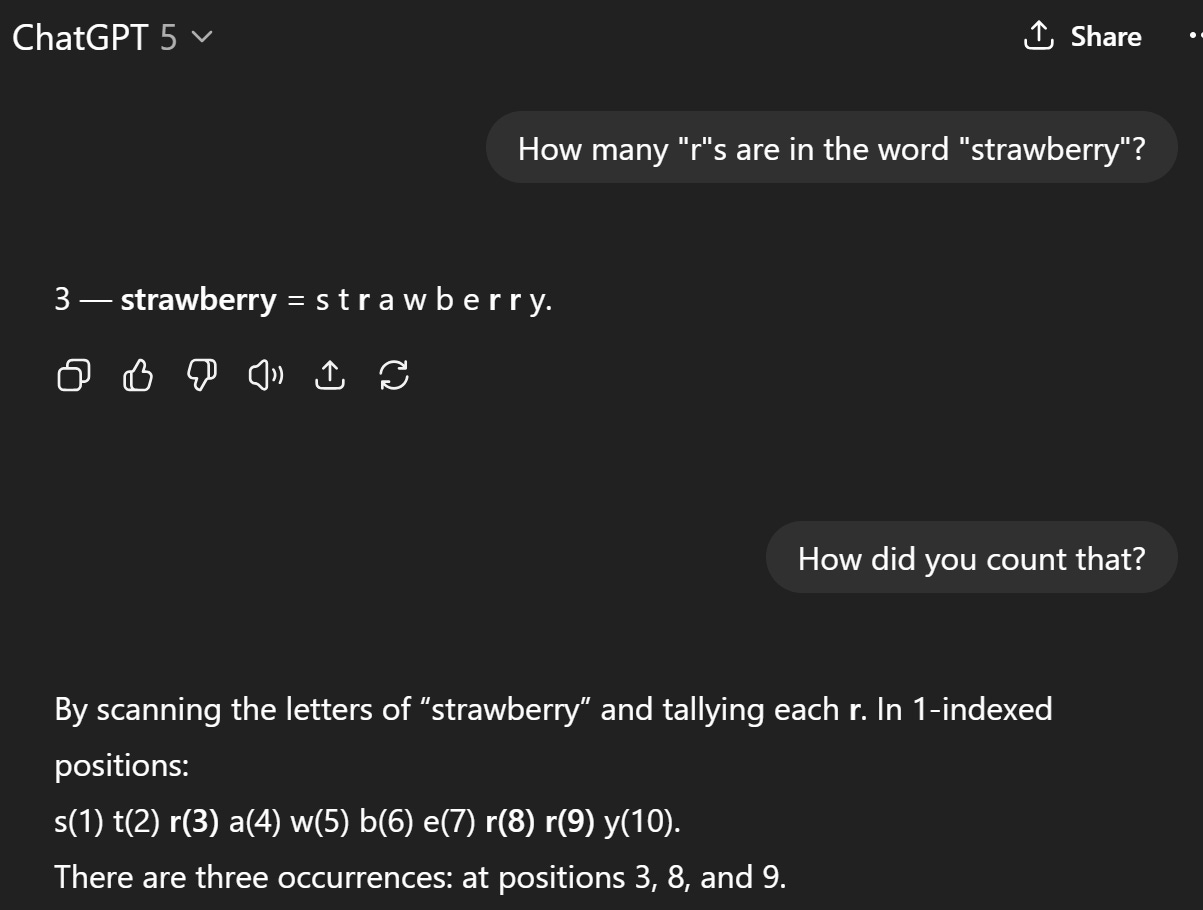
Is GPT5 that much smarter than GPT4? I don’t know. But I am reasonably confident that that OpenAI engineers specifically trained GPT5 on this kind of prompt.
Tokenization in different languages
English both is and isn’t a special language. It isn’t a special language because it’s just a form of human communication; just one of the many thousands of languages spoken today and just one of the many tens of thousands of languages that humans have ever invented.
But on the other hand, English is by far the most well-represented language on the web, which is mostly what LLMs are trained on. There is simply more English in the training data than any other language. This means that tokenizers have a lot more data to find optimal chunking patterns in English compared to any other language. On the one hand, AI companies can compensate by overtraining on less represented languages, or getting new data in other languages. But let’s face it: The big AI companies like OpenAI, Microsoft, Meta, etc., are not building these models for charity, so they’re not going to invest millions of dollars to train on a language from a poor country that can’t afford a lot of subscription plans.
Anyway, the point is that it’s interesting to see what tokenization looks like in different languages. I machine-translated the following sentence into different languages.
Blue towels are great because they remind you of the sea, although the sea is wet and towels work better when they are dry.
And then I tokenized those sentences. Here’re the results:
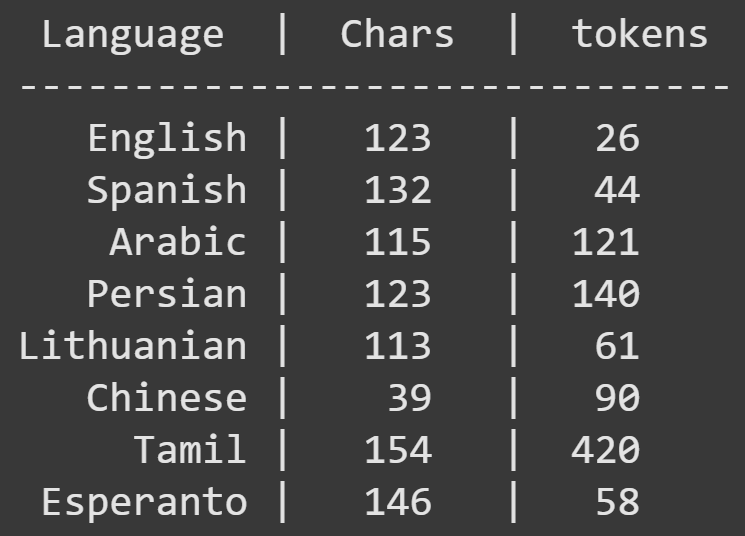
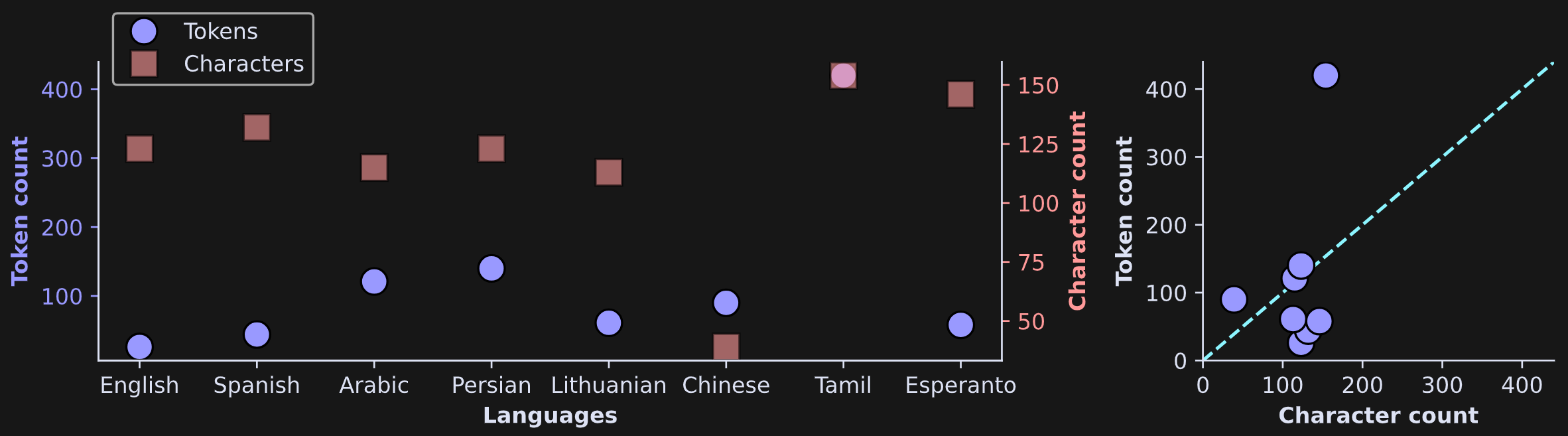
Quite striking! In this example, English was the most compressed (defining “compression” as tokens / characters). Chinese and Tamil actually had more tokens than characters! That might seem surprising, but it’s due to the fact that the byte-pair encoding algorithm is based on bytes not characters, and individual Chinese characters comprise multiple bytes.
Figure 10 below shows the same information visually. The scatter plot on the left shows each language on the x-axis, and the scatter plot on the right shows the relationship between character and token count. Data points below the diagonal indicate text compression, while data points above the diagonal indicate an expansion from tokenization (more tokens than characters).
Tokenization in BERT
The last thing I want to demonstrate in this post is that tokenizers are model-specific. Even within the same organization, models of different sizes (that is, different parameter counts) often have different tokenizers. For example, GPT2’s tokenizer has a vocab over just over 50k while GPT4’s vocab is around 100k. Never use the tokenizer from one model with a different model, unless you’ve confirmed that the two models use the same tokenizer.
I’ll demo this by importing the BERT tokenizer. BERT is a language model developed by Google. It has a lot of similarities to OpenAI’s GPT models, but also some key differences stemming from the fact that GPT is designed for language generation whereas BERT is designed for classification.
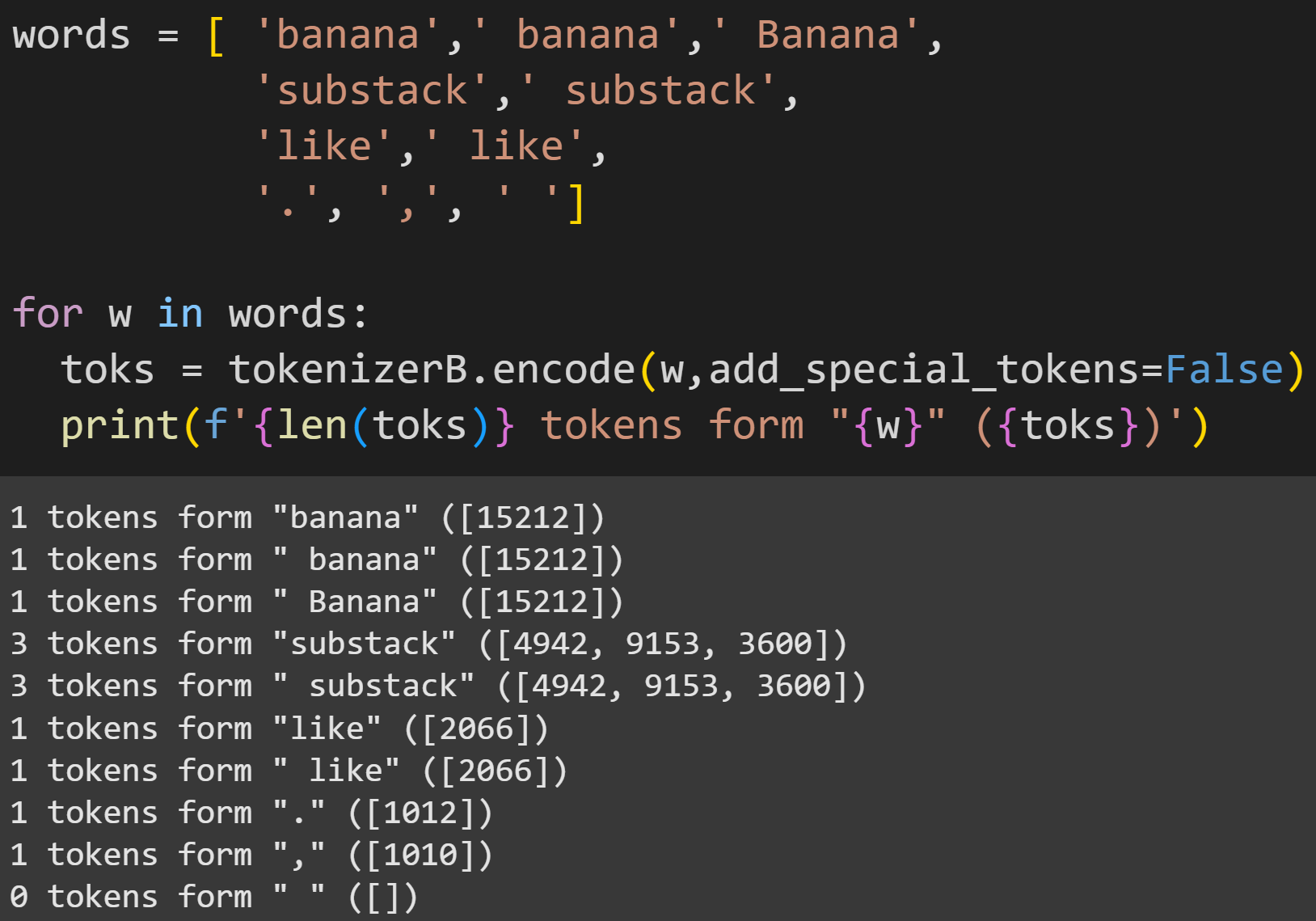
These results are remarkably different from the GPT tokenization. Two remarks:
BERT ignores preceding spaces, and also capitalizations. (In fact, there are different tokenizers for BERT; the one I imported is uncased.)
Not only does BERT ignore preceding spaces, it ignores all spaces. The space is literally missing from the tokenizer’s vocab, which is why the final output line says that there are 0 tokens in “ “.
Why are BERT and GPT tokenizations so different? The short answer is that GPT-style models are trained to generate new text, whereas BERT-style models are designed to categorize text. If your goal is to label, e.g., an Amazon product review as positive or negative, then you don’t care about spaces and capitalizations. Those two different goals led to two different tokenization schemes and training regimens. The key difference is that BERT-style models are trained without causality (they can see all tokens simultaneously) whereas GPT-style models are trained with causality (they can see only tokens before, but not after, each token). I’ll have more to say about that in Post 5 in this series.
You read this far; I’m proud of you (and so is your Grandma)
I hope you are finding my Substack posts useful and valuable (maybe even a tiny bit entertaining… maybe). I’m not a religious person and I don’t believe in “Destiny,” but I do feel like creating high-quality, low-cost, widely accessible education is “my calling.” I quit my cushy tenured professorship to do this full-time. If you think I should keep doing it, please support me by enrolling in my courses or buying my textbooks. And share my work with your Grandma. And anyone else.
And if you’re particularly interested in a deep-dive into language model architecture and mechanisms, check out my LLM mega-course.
Video code walk-through
The 18-minute video below is me explaining the code and findings in more detail. It is available to paid subscribers.
Keep reading with a 7-day free trial
Subscribe to Mike X Cohen to keep reading this post and get 7 days of free access to the full post archives.